当世界模型不止「视频」该如何评估?WorldLens提出实用化评估新框架(模型是现实世界)

生成式世界模型在机器人、自动驾驶、AIGC等领域的进展肉眼可见:从单视角、行车记录仪式的视频合成,到可控、多视角、长时序的 4D 场景生成,越来越多系统已经能输出「看起来很逼真」的视频画面。
但问题也随之变得尖锐:当一个模型被称为「世界模型」时,我们究竟在期待它具备什么能力?
仅用 LPIPS、FVD 这类视频指标,或「清晰 / 流畅 / 像真视频」的主观印象,很容易把讨论停留在「像不像视频」。而真正决定它是否能服务仿真、规划、数据合成和闭环决策的,往往是那些视频指标难以触及的属性:几何是否自洽、多视角是否一致、时序是否稳定、行为是否可执行、下游是否可用、人类是否认可其物理与安全合理性。
近期,WorldBench 团队构建了全新、体系化的世界模型评测框架 WorldLens。
据悉,这是领域内首个从生成 (Generation)、重建 (Reconstruction)、指令跟随 (Action-Following)、下游任务 (Downstream)和人类偏好 (Human Preference)等五个维度同时出发,评测现有开源世界模型的框架。评测 EvalKit 现已公开。

- 论文链接:https://arxiv.org/abs/2512.10958
- 项目主页:https://worldbench.github.io/worldlens
- 开源评测代码库:https://github.com/worldbench/WorldLens
- 官方 Leaderboard:https://huggingface.co/spaces/worldbench/WorldLens
为什么「世界模型评估」会成为瓶颈?
世界模型研究正快速从「能生成」走向「能用」。一旦它被放进真实链路,如作为仿真器用于闭环测试、作为数据引擎用于训练感知与规划、作为可交互环境支撑反事实推演,评估问题就不再是「文章里有没有几个指标」,而是决定整个方向能否规模化推进的基础设施。
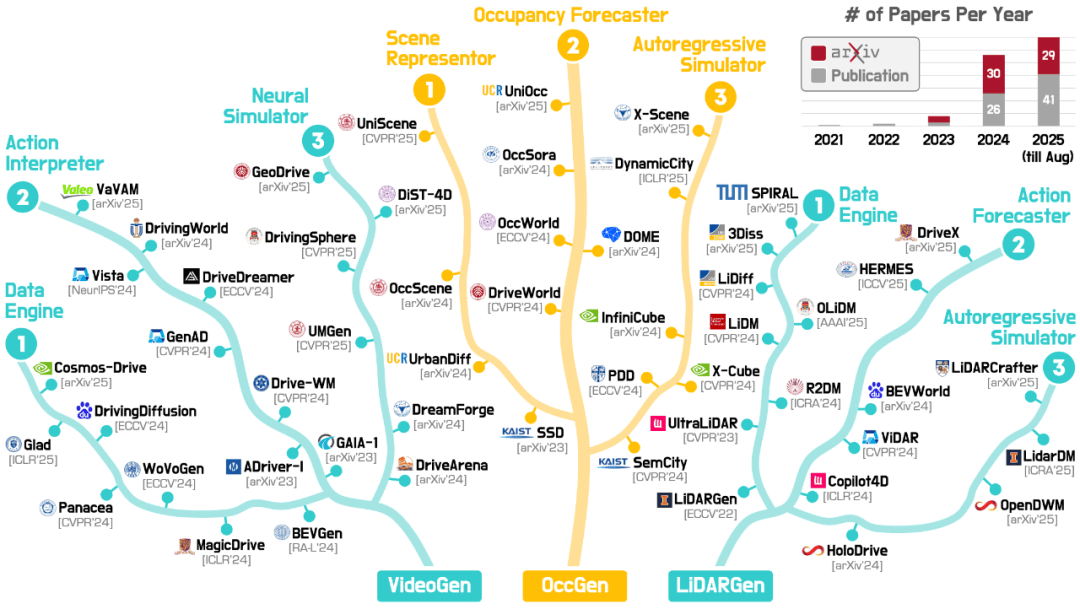
现实中,我们经常看到一种现象:有的模型生成的视频纹理很强、观感极佳,但多视角几何对不上,时序也容易抖;有的模型几何更稳,却在行为层面频繁出现不合理运动;也有模型在开环指标上看似过关,但闭环很快崩掉。更麻烦的是,不同工作各用各的评测,结论难以对齐,失败模式也难以复现与归因。
WorldLens 的核心动机很明确:评估对象已经从「视频」变成「世界」,那么我们需要一套能覆盖世界属性 (World Attribute)、能诊断失败来源、能在不同模型间公平对比的评测协议。
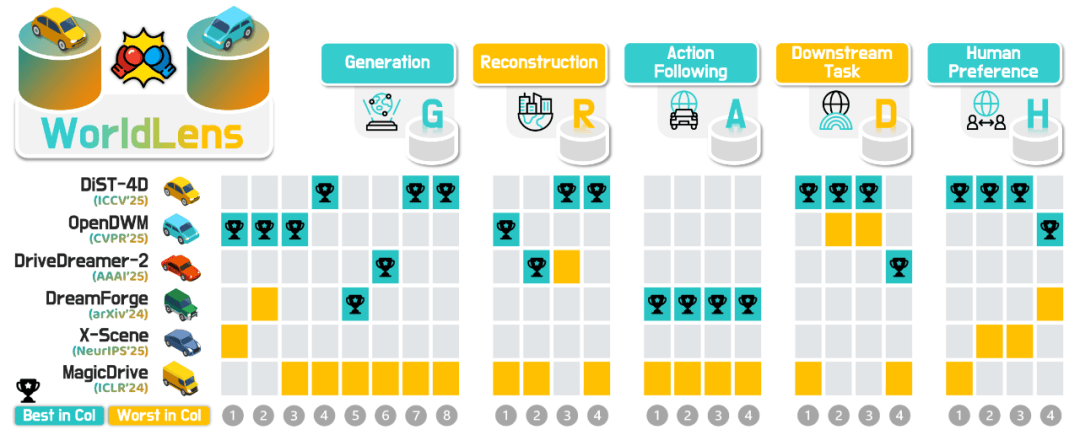
WorldLens 是什么
WorldLens并不试图用一个分数给世界模型「盖棺定论」,而是把评估拆成五个互补的 Aspect,让每个 Aspect 回答一个现实问题:
- 生成 (Generation):模型生成的画面是否在对象、时间、语义、几何、多视角层面都足够可信?
- 重建 (Reconstruction):这些序列能否被还原成一个稳定的 4D 场景,并在新视角下仍然成立?
- 指令跟随 (Action-Following):把生成世界「喂」给规划器,Agent 还能不能「正常运行」?尤其是在闭环条件下。
- 下游任务 (Downstream Task):用它生成的数据训练 / 测试真实感知任务,是帮助还是负迁移?
- 人类偏好 (Human Preference):人类看完是否会觉得「可信」「合理」「安全」?这种判断能否被规模化学习成自动评估器?
如果把世界模型看作一种新的「系统级组件」,这五个方面分别对应它在真实落地链路中的五个关键关卡:看得像、立得住、跑得动、用得上、说得通。
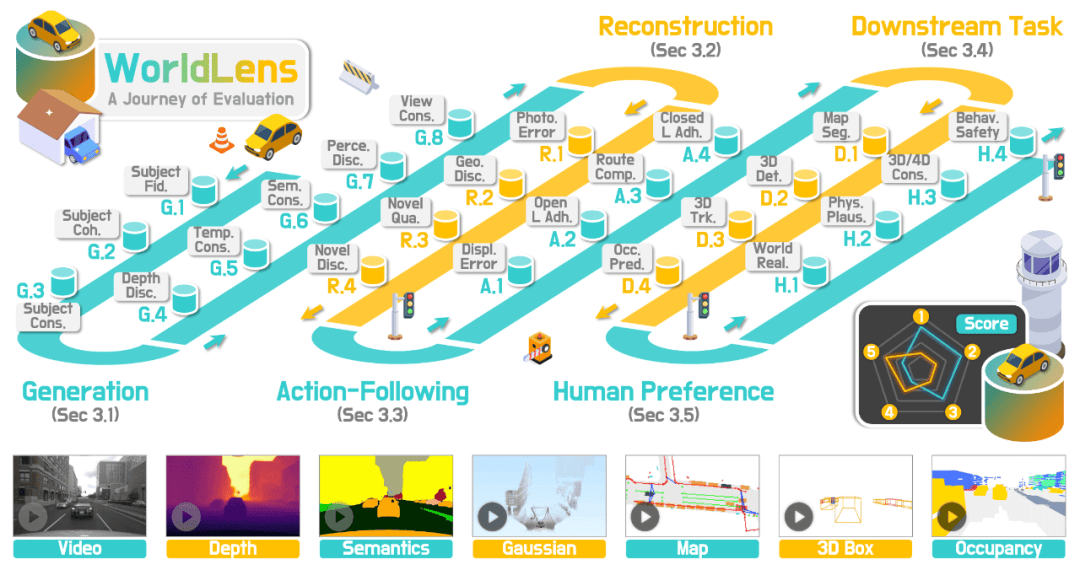
Aspect 1: 生成 (Generation) ——「帧级真实」只是起点
很多世界模型最先打动人的,是单帧画面的清晰度与质感。但只要把镜头拉长到时序、把设置扩展到多摄像头,就会出现大量「视频指标不敏感,但真实系统非常在意」的问题。
WorldLens在生成性评估这一部分,重点不是继续追问「更像真实视频了吗」,而是把生成质量拆到更贴近世界属性的层面。它会在对象层面检查车辆、行人等关键参与者是否真实可信(例如外观与语义是否对齐),也会在时序层面检查同一个对象是否能稳定地保持「同一个身份」,避免出现纹理闪烁、形状漂移、甚至像换了一个实体的情况。
更关键的是,WorldLens把几何与多视角一致性拉回到生成评估中心。即便模型不直接输出深度,它仍然可以通过估计深度来观察几何随时间是否平滑演化,从而捕捉到隐式几何不稳定;同时,通过跨视角匹配衡量相机之间的结构与光度对齐,直接检验生成「多视角世界」的能力。
Aspect 2: 重建 (Reconstruction) —— 如果是「世界」,就应当能被重建
「像世界」不只是看起来合理,更重要的是它是否隐含一个可以被还原的稳定结构。WorldLens在重建方面做了一件很有辨识度的事:把生成视频统一提升为 4D Gaussian Field,再从多个角度检验它的空间与时间一致性。
在原视角上,它关心重建后能否忠实再现输入(也就是最基础的光度 / 外观重现);但更有信息量的是新视角评测:沿着未见过的相机轨迹渲染新视图,看是否会出现结构崩坏、遮挡错误或明显伪影,并衡量新视图与真实分布之间的差距。
这一套流程经常会暴露出一种典型失效模式,也即论文中反复强调的「floaters」:在新视角下出现大量悬浮、不连续的几何碎片。它非常直观地揭示了一个事实:感知真实不等于几何真实。一个模型可以把纹理做得极其逼真,但只要几何与时序没有被真正建模,新视角就会迅速「露馅」。

Aspect 3: 指令跟随 (Action-Following) —— 能「看」,不代表能「用」
如果世界模型要进入自动驾驶的核心链路,绕不开的一步是:把它生成的世界交给规划器,看系统还能不能跑起来。WorldLens在这一部分同时做了开环与闭环评测,目的不是「给规划器打分」,而是把规划器当作媒介,测试生成世界是否提供了足够稳定、足够可信的可行动线索。
开环评测里,规划器的输出不反过来影响车辆状态,因此更像是「在固定输入上做预测」。不少模型在开环条件下仍能表现得相对体面。但一旦进入闭环,规划输出会不断影响下一时刻状态,误差会累积放大,许多模型会很快出现碰撞、越界、漂移、路线中止等问题。WorldLens 给出的结论非常一致:闭环会显著放大生成世界中那些肉眼未必立刻察觉的不一致。
如果你的目标是用世界模型服务决策与控制,那么闭环评测就不应当是「可选项」,而应当是「必要条件」。WorldLens 的意义在于把这件事从经验共识变成可复现的评估协议。
Aspect 4: 下游任务 (Downstream Task) ——「好看」的合成数据,未必「有用」
世界模型的另一个常见愿景,是成为数据引擎:生成更多训练数据,帮助真实感知与预测模型。但合成数据是否「可用」,往往不是由视觉观感决定的,而是由分布对齐、几何噪声与时间一致性决定的。
WorldLens 直接把生成数据拿来评测多个真实下游任务,包括 BEV 地图分割、3D 检测、3D 跟踪与语义 Occupancy 预测等。这里最具冲击力的现象是:一些单看画面非常漂亮的模型,在下游任务上反而会出现显著退化,论文中报告的降幅可达 30–50%。这意味着合成数据并不能被简单视为真实数据的等价替代,甚至可能带来负迁移。
这部分评测的价值在于,它把「世界模型是否有用」从理论讨论落到了具体任务与具体数字上,并且指出了改进方向:如果目标是数据引擎,仅提升纹理质量远远不够,结构与时间层面的对齐往往才是关键。
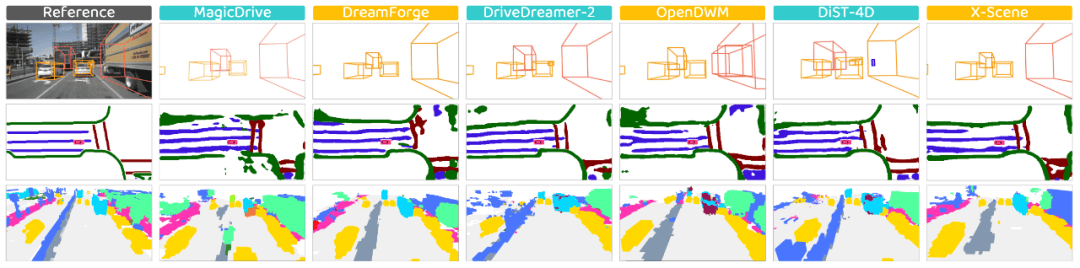
Aspect 5: 人类偏好 (Human Preference) —— 把「人类判断可信世界」变成可学习信号
很多世界属性 (World Attribute) 本质上包含主观判断:什么叫「可信」「合理」「安全」?纯自动指标很难覆盖这种综合感受。
WorldLens因此构建了大规模人类偏好数据集 WorldLens-26K,包含 26808 条评测样本,每条既有数值评分,也有自然语言解释,用来记录标注者为什么给出这个分数、注意到了哪些异常。
更重要的是,WorldLens并没有把人类评测停留在「投票式打分」,而是把这些偏好监督进一步用于训练自动评估代理 WorldLens-Agent。该 Agent 能输出与人类偏好一致的评分,并生成可解释的理由,从而在不重复大规模人工标注的前提下,实现可扩展、可复现的主观评估。
从研究视角看,这一步相当于把「人类觉得哪里不对」转化成了可学习、可迭代的评估器,也为未来用偏好对齐来反向优化世界模型打开了路径。

没有「全能模型」,但失效模式高度一致
WorldLens 的价值不止于 benchmarking,更在于用统一评估把不同模型的能力边界与失效模式系统性地暴露出来。跨五个 Aspect 的结果呈现出几个非常稳定、也很值得反复咀嚼的现象。
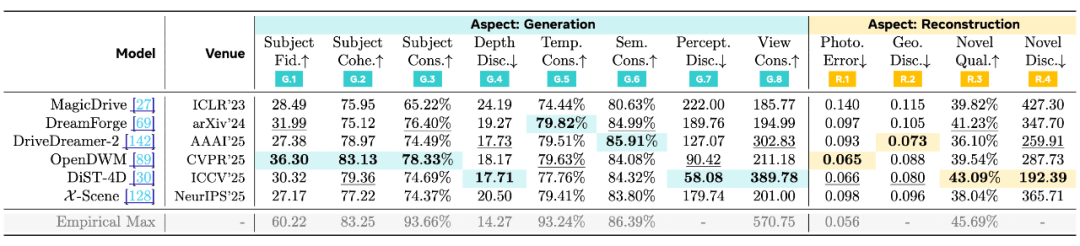
首先,不同 Aspect 之间存在明显的能力断层。Generation 指标上领先的模型,未必能在重建与新视角上站得住;单视角观感极佳的模型,跨视角一致性可能依然脆弱;开环还能勉强运行的模型,闭环往往迅速失稳。这说明世界模型的能力并不是一条从差到好的线性刻度。
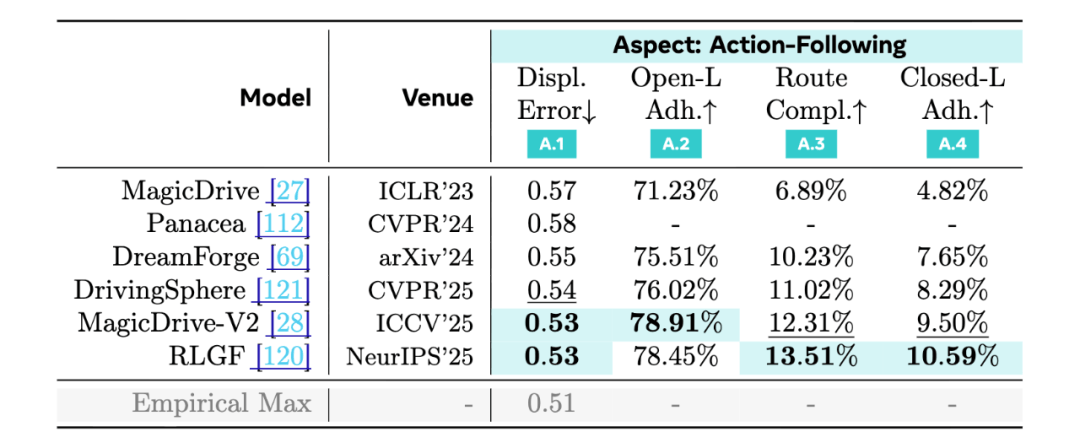
其次,几何与时序稳定性像一条「共同瓶颈」,贯穿 Generation、Reconstruction、Action-Following 乃至 Downstream Task。几何不稳会在新视角下暴露为 floaters,也更容易在闭环中放大为事故,并进一步拖累下游任务表现。
这也解释了一个常见困惑:为什么某些模型看起来更清晰,却不一定更可用 —— 因为纹理质量并不能替代世界结构的自洽。
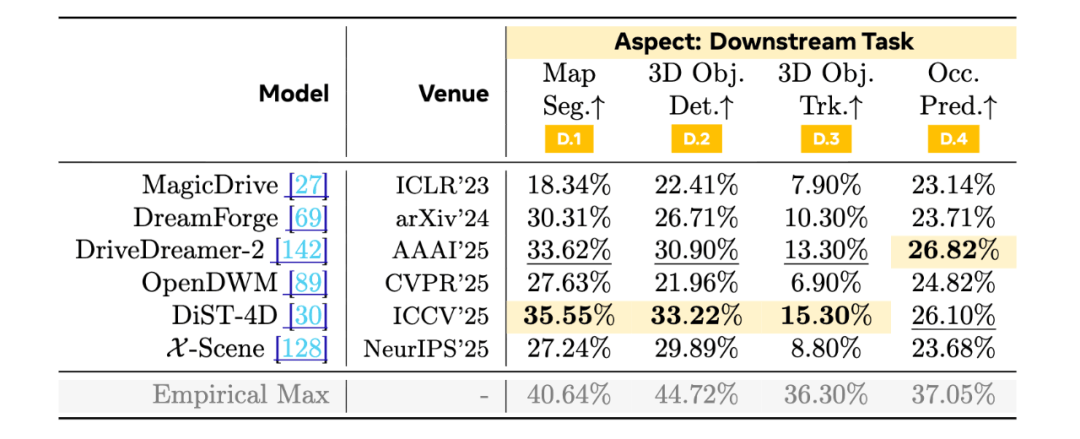
再次,闭环评测会把世界模型的缺陷放大到「无法忽视」。在闭环中,任何微小的不一致都会持续积累,最终表现为碰撞、偏航与路线失败。这对于希望把世界模型用于仿真、验证与安全测试的研究者而言,是非常直接的提醒:如果只在开环里「看起来不错」,距离真实可用仍然很远。
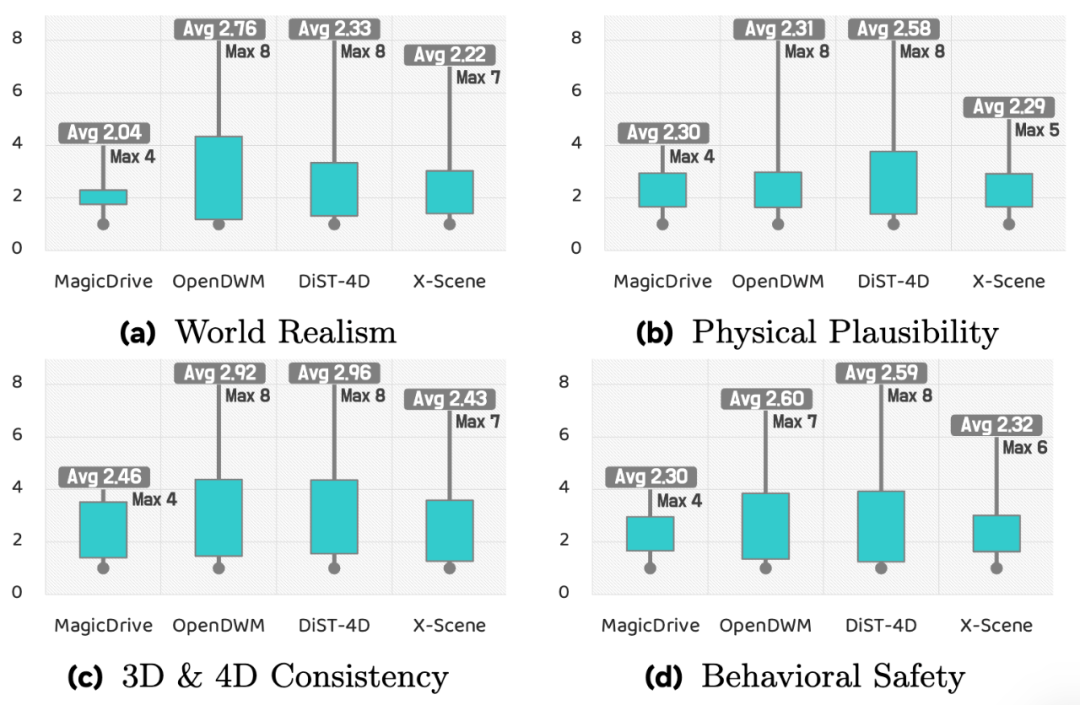
最后,人类偏好与自动指标既相关又不完全一致。人类解释文本往往会直接指出几何异常、物理违背与行为风险,这些信息对理解失败原因非常关键,也为自动评估代理提供了训练依据。换句话说,主观评估并不是「不可量化的玄学」,而是可以被结构化、被学习、并最终进入评估闭环的一部分。

总结:评估将与生成同等重要
当世界模型从「生成好看的片段」走向「构建可交互的世界」,评估就必须从「视频质量」升级为「世界属性」。WorldLens 的贡献在于把这件事做成了可执行的协议:用五个 Aspect 覆盖从视觉到几何、从功能到偏好的一整条链路,并用人类数据与评估代理把主观判断也纳入可规模化的体系。
如果说世界模型的上半场比拼的是「能不能生成」,那么下半场更可能比拼的是:能不能生成一个在几何、物理、行为与人类判断上都经得起检验的世界。WorldLens 试图为这场下半场提供一套共同语言。
作者介绍
本工作由 WorldBench 团队完成,该团队汇集了来自世界模型、视频生成、自动驾驶等方向的研究者,在领域内构建了体系化、易用、性能可靠的各类生成 / 评测框架,包括 VBench、LiDARCrafter、DynamicCity、DrivingSphere、AD-R1 等
研究者来自世界知名高校、企业,包括了新国立、中科院、中科大、浙大、澳门大学、地平线、南洋理工、华科、慕尼黑工大、复旦、上海人工智能实验室等










